はじめまして、GMOあおぞらネット銀行でエンジニアをしているT.Kです。
普段は当社CTO直下部署で、新規技術調査や新規サービスなどの先行調査・検討などを行っています。
初めてのはてなブログとなりますが、複数回でGoogle Cloud Platform(以下、GCP)に構築した分析基盤に関してブログを書きたいと思います。
今回は、当社データセンターからBigQueryへの登録までに触れていきます。
GCP上にシステム構築を行ったのは初めての為、イマイチな部分も多くありますが、今後のより良い形に改善していきたいと考えています。
概要

今回のブログでは、上記イメージ図のオンプレ⇒DWH部分にフォーカスしていきます。
初期要件としては、『連携は1日1回〜2回程度、合計約50MBのファイルを個別に受信し、共通DWHへ登録したい』となります。
データ活用部分やセキュリティを意識した開発環境構築などに関しては、次回以降のブログで紹介できればと考えています。
情報基盤要件と方針
- データ連携頻度は1日に数回
汎用性と運用効率の面からスケジューラは利用しない
バッチ式で対応 - 将来的に連携データ量(ファイル数)は増加想定
運用負荷軽減の為、コード内に連携データ固有の処理を記述しない - 連携データを利用した後続プロジェクトが存在し、将来的には増加想定
データ取込処理は5分以内で完了する - 当社セキュリティ基準をクリアする環境構築 (※次回ブログ予定)
構築の流れ

1. Cloud Storageの準備
バケット作成 & 各種設定
- バケットを作成にはお金は掛からない為、用途別に複数作成
- Cloud FunctionからGCSへ処理が行われるケースでは、"アクセス制御"を"きめ細かい管理"にしないとエラーが発生したので、一旦"きめ細かい管理"設定
- 不要ファイルはライフサイクルで対応
バケット用途 |
アクセス制御 |
ライフサイクル |
備考 |
|---|---|---|---|
受信用バケット |
きめ細かい管理 |
【削除】最終更新後1日 |
Cloud Functionからデータ読込 |
一時保存用バケット |
均一 |
【削除】最終更新後1日 |
|
backup用バケット |
きめ細かい管理 |
【削除】最終更新後60日 |
Cloud Functionからデータ書込 |
設定用バケット |
均一 |
- "アクセス制御"はバケット作成時に選択

- "ライフサイクル"はバケット作成後、バケット詳細から設定

- 1日後に削除するライフサイクル設定例


2 外部ファイル準備
今回の仕組みでは、2つのCloud Function処理で利用する、設定ファイルとmerge用SQLが対象となります。
連携データ(ファイル)固有の情報を外部ファイルに切出した為、外部ファイル更新のみで、連携データの更新が可能な仕組みとなっています。
3. 第一弾処理(Cloud Function)の作成
幾つかにポイントを絞って触れていきたいと思います。
ⅰ. jsonファイルの読込
- json形式のファイルはライブラリを利用する事で簡単に読み込む事が可能
# ライブラリの読込 import json # ファイル内容読取 blob = bucket.blob("property.json") # 変数にjson形式で読取 property_file = json.loads(blob.download_as_string())
ⅱ. Google Cloud Storage間のファイルコピー
- 送信先バケットに指定フォルダが無くても、自動作成
- コピー元とコピー先バケットのアクセス制御が『きめ細かい管理』設定でないとエラー発生
- Cloud Functionが利用するサービスアカウントへ適切な権限を付与
# GCSライブラリ読込 from google.cloud import storage # コピー元バケット bucket = storageClient.get_bucket(backetName) # コピー先バケット backupBucket = storageClient.get_bucket(backetName) # 保存先パス new_blob = bucket.copy_blob(blob, backupBucket, new_name= "バケットパス+日付とか" + '/' + "ファイル名") # 保存 new_blob.acl.save(blob.acl)
ⅲ. zip解凍処理
- 圧縮ファイル解凍時、ファイル内容は一旦メモリに保存されるので、メモリ設定は特に注意
Cloud Functionの処理自体にも一定量メモリが必要の為、多少余裕が必要 - 現在Cloud Functionは最大8GBまで"割り当てられるメモリ"を設定可能だが、もし8GBを超える圧縮ファイルを取扱うケースでは、別構成を検討
# zipライブラリ読込 from zipfile import ZipFile from zipfile import is_zipfile # GCS上の対象ファイルを設定 blob = bucket.blob(destination_blob_pathname) # ファイル読込 zipbytes = io.BytesIO(blob.download_as_string()) # zip形式可否チェック if is_zipfile(zipbytes): # zipファイル解凍 with ZipFile(zipbytes, 'r') as myzip: # 解凍ファイルを個別に処理 for contentfilename in myzip.namelist(): # 解凍ファイル読込 contentfile = myzip.read(contentfilename) # 保存先バケットパスを設定 blob = outbucket.blob("ファイルパス" + "/" + contentfilename) # 解凍ファイル保存 blob.upload_from_string(contentfile)
ⅳ. デプロイ
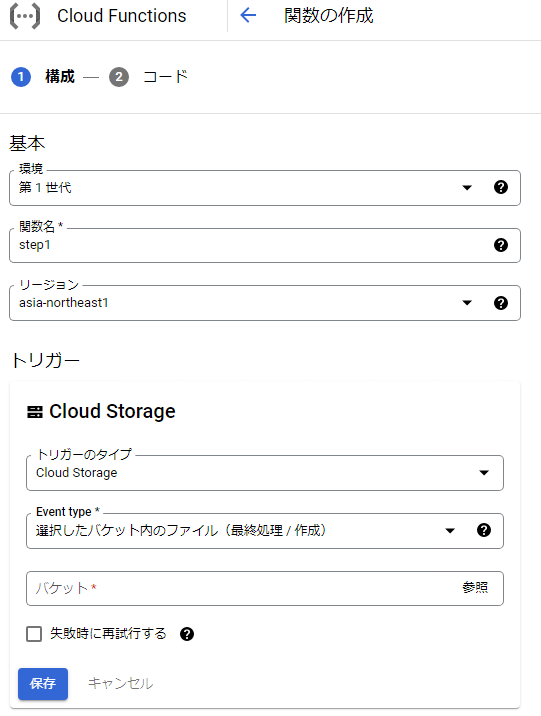
- トリガー設定 ※左画像
- "トリガーのタイプ"に『Cloud Storage』を選択
- "Event Tyep"に『選択したバケット内のファイル(最終処理 / 作成)』を選択
- "バケット"に"起動条件バケット"を選択
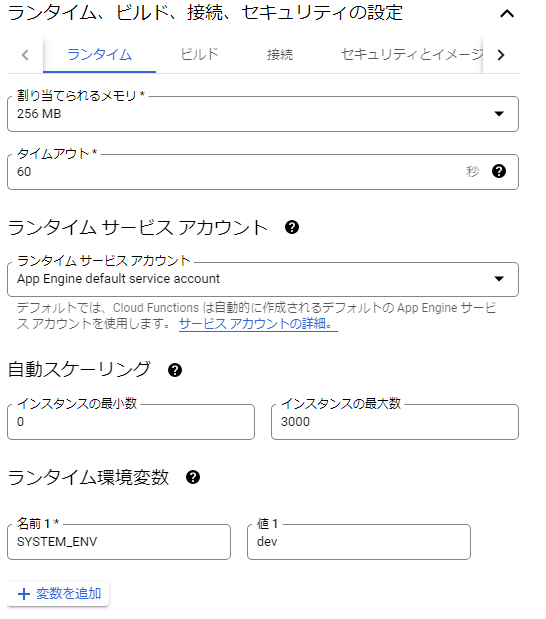
- メモリ設定 + α ※右画像
- 解凍ファイルサイズ等に合わせて、適切な値を選択
- 想定処理時間等に合わせて、タイムアウトを設定(最大540秒)
- 必要に応じて、環境変数設定
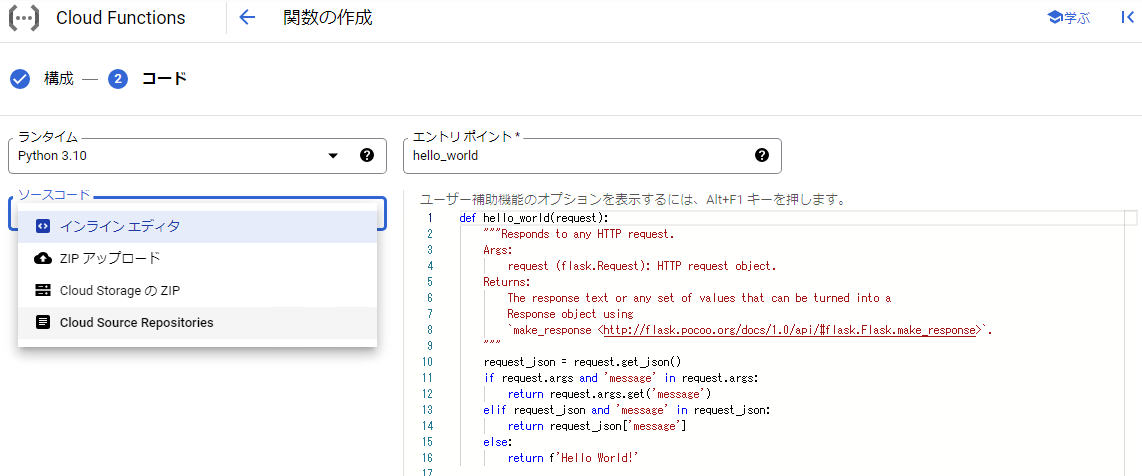
- デプロイ対象コード
- コードは"インラインエディタ"で直接記述する事や"Cloud Source Repositories"からソースを展開する事が可能
"Cloud Source Repositories"のソース編集はcloud shellなどを利用する必要があります
- コードは"インラインエディタ"で直接記述する事や"Cloud Source Repositories"からソースを展開する事が可能
4. 第二弾処理(Cloud Function)の作成
こちらもポイントを絞って触れてきます
ⅰ. 既存TBLのスキーマ情報取得
- 一時TBL用のスキーマ情報を読込
- 補足
BigQueryは賢いので、スキーマ未指定でもデータ取込処理の実行は可能だが、都度取込データに依存したデータ型が選択されてしまう為、型にブレが出る事に注意
# BigQueryのライブラリ読込 from google.cloud import bigquery # BigQueryのクライアント作成 client = bigquery.Client() # スキーマ取得元のテーブルID設定 table_id = os.environ.get('GCP_PROJECT') + "." + property["secondStep"]["bigquery"]["dataset"] + "." + fileName # スキーマ取得元のテーブル情報設定 tableInfo = client.get_table(table_id) # 1項目ずつスキーマ情報を設定 for field in tableInfo.schema: if count < len(tableInfo.schema): schemaList.append(field) count = count+1
ⅱ. BigQueryへデータ登録
- 受信ファイルのデータを一時TBLへ登録
# BigQueryのライブラリ読込 from google.cloud import bigquery # データ登録用コンフィグ設定 job_config = bigquery.LoadJobConfig() # スキーマ情報読込 ※ ⅰの処理を行うfunction呼出 job_config.schema = getSchema(file_name.replace(property["common"]["dc_file_prefix"], '')) # 取込データ1行目SKIP ※項目名等が存在する事を想定 job_config.skip_leading_rows = 1 # 取込データ形式設定 job_config.source_format = bigquery.SourceFormat.CSV # 引用符で囲まれた改行を許可設定 job_config.allow_quoted_newlines = True # 上書き設定 ※新規TBLへの登録なので不要かも… job_config.write_disposition = 'WRITE_TRUNCATE' # 一時TBLのIDを設定 table = bigquery.Table(table_id_temp) # 作成先、IDとコンフィグ情報を設定 job = client.load_table_from_uri(uri, table, job_config=job_config) # 一時TBL作成処理実行 job.result()
ⅲ. 外部ファイルからSQL文を読込・実行
- 既存TBLと一時TBLを利用したmerge文を実行
各TBL用のmerge文を外部ファイルに切出しましたが、既存TBLのスキーマ情報を利用すれば自動生成する事も出来そうですね
SQLサンプルはmerge SQL sample参照
# BigQueryのライブラリ読込 from google.cloud import bigquery # BigQueryクライアント設定 client = bigquery.Client() # 登録先TBL用のmerge文を外部ファイルから読込 ※functionの詳細は"第二弾 code"参照 query = getSettingValues(file_name + ".csv", "mergeQueryPath") # 実行時に不要な改行コードを削除 ※外部ファイル上では見にくいので改行コードしている為 query = query.format(table_id, table_id_temp).replace('\n' , '') # merge文設定 job = client.query(query) # merge文実行 job.result()
ⅳ. デプロイ
- トリガー条件のバケット以外、第一弾処理と同様
5. BigQueryの設定
BigQueryに関しては登録用のTBLを作成しておくだけなので、適宜CRETE文などを実行して作成すればOK
結果
方針達成に関して
- スケジューラは利用しない & バッチ式で対応
- GCSへのファイルアップをトリガーにBigQuery登録までの処理を自動化
- コード内に連携データ固有の処理を記述しない
- 取込データ固有の内容に関しては、全て外部ファイルに切出す事で対応
固有情報を切出した事で、取込データ追加等の対応に関しても基本的にコード改修不要
- 取込データ固有の内容に関しては、全て外部ファイルに切出す事で対応
- 5分以内で完了
- 下記、稼働後10日程の平均処理時間
ファイルアップロードからBigQuery登録完了までの処理を約1分程度で完了。将来的なデータ増加に伴い、処理時間増加は想定されるが、ある程度余裕がある結果となった。
- 下記、稼働後10日程の平均処理時間
| 受信ファイルサイズ | 第一弾処理時間 | 第二弾処理時間 | 処理合計時間 |
|---|---|---|---|
約60MB |
15秒 |
46秒 |
61秒 |
その他
- 利用コストに関して
- 下記、稼働後10日間の各サービスの平均費用額
BigQueryの費用は他と比べ高めだが、Cloud Functionの費用がかなり安い結果となった。BigQueryの費用に関しては、merge文が影響している可能性があるので別途調査予定
- 下記、稼働後10日間の各サービスの平均費用額
| Cloud Storage | Cloud Function | BigQuery |
|---|---|---|
76円 |
39円 |
1,950円 |
まとめ
今回フォーカスした仕組みに関しては、(日々の連携ファイルサイズが小さい事もありますが)受信ファイル毎に並列実行可能な仕組みとした事で、処理時間に関しては全く問題ない結果となりました。
また、連携データ毎固有部分を外部に切り出せた事で、Cloud Functionのコードをシンプルに構成する事が出来ました。(必ずしも外部に切り出せば良い訳ではありませんが…)
利用費用に関しては、一部調査課題を残していますが、現状問題ない範囲で収まっている印象です。
今回の連携データではデータ加工処理が不要であった為、Cloud StorageとCloud Functionの組み合わせで特に問題はありませんでしたが、理想はDataflowを利用するべきだとは感じてました。将来、同様の仕組みを構築する場合にはDataflowに挑戦してみたいと思います。